Everything starts with a manual test case.
Our test case is for the Vancouver Public Library site.
It tests that a search done on the site’s home page returns results.
The test case tell us what actions the user takes
1. user opens home page
2. user searches for keyword
to verify if the result is correct:
3. user verifies that results page is opened
4. user verifies that there is at least 1 result for the search
Our goal is to automate this test case using Selenium WebDriver, Java and the page object model.
Before writing any code, we will convert the test case to a format suitable for test automation.
This will happen in a few iterations.
1. PREPARE THE TEST CASE FOR AUTOMATION
1.1 GROUP TEST CASE ACTIONS BY PAGE
First, we group the test case actions and verifications by the page where they happen:
HOME PAGE
1. open home page
2. search for keyword
RESULTS PAGE
3. verify that results page is opened
4. verify that there are results for the search
1.2 BREAK DOWN TEST CASE ACTIONS IN SUB-ACTIONS
The test case actions tell us WHAT the user does to be able to make verifications.
Both the user actions and the verifications are defined at a high level so far.
We will decompose each test case action in sub-actions that describe HOW the action is executed by the user.
When decomposing actions in sub-actions, we will determine as well what is required by each sub-action.
HOME PAGE
1. OPEN HOME PAGE
Required: home page url
2. SEARCH FOR KEYWORD
2.1 click search text box
Required: search text box locator
2.2 type keyword in search text box
Required: search text box locator, search keyword
2.3 click search button
Required: search button locator
RESULTS PAGE
3. CHECK THAT RESULTS PAGE IS DISPLAYED
3.1 get page title
Required: page title
3.2 verify that page title is correct
3.3 get page url
Required: page url
3.4 verify that page url is correct
4. CHECK THAT THE SEARCH RETURNS RESULTS
4.1 get results count value
Required: result count label locator
4.2 verify that results count value is > 0

We have so far 3 types of sub-actions:
- sub-actions that do something
1.1 open page using home page url
2.1 click search text box
2.2 type keyword in search text box
2.3 click search button
- sub-actions that provide information about page elements
3.1 get page title
3.3 get page url
4.1 get results count value
- actions that assert (verify) that information is correct
3.2 verify that page title is correct
3.4 verify that page url is correct
4.2 verify that results count value is > 0
1.3 CONVERT ACTIONS AND SUB-ACTIONS INTO METHODS
Each action and sub-action will be implemented by a method as follows:
- If the action does something. the corresponding method does not return a value.
- If the action provides information, the corresponding method returns a value.
- If the action verifies that information is correct, an assertion is used.
Methods may have parameters (example: search() method uses a parameter for the keyword).
If a method interacts with a page element, it will use a locator variable for the element.
HOME PAGE
1. public void openPage(String homePageUrl)
2. public void searchForKeyword(String keyword)
This method executes the search with the help of 2 other methods:
typeSearchKeyword(keyword);
executeSearch();
These methods use 2 locator variables:
String searchTextBoxLocator;
String searchButtonLocator;
RESULTS PAGE
3. verifyThat(getPageTitle() == expectedResultsPageTitle);
verifyThat(resultsPageUrl == expectedResultsPageUrl);
getPageTitle() provides current page title.
getPageUrl() provides the current page url.
4. verifyThat(resultCount() > 0);
resultCount() provides the count of results.
It uses a locator variable for the results count label (resultCountLabelLocator).
We have what we need for the test automation script:
- methods to be implemented
- variables that the methods need
- methods and variables are grouped by page
3 components are required for the test automation script to work:
2. CREATE THE TEST CLASS
Each test automation script implements one test case.
A test script is created in a test class which may include multiple test scripts.
If a test script is equivalent of a test case, a test class is equivalent of a suite of test cases.
2.1 Component of a test class
The components of the test class are
a) setUpEnvironment() method
A test script needs a test environment to be executed in.
The test environment consists in
1. browser where the site is loaded
2. browser driver for driving the site in the browser
setUpEnvironment() method creates the test environment for the test script.
It executes before each test script because of the @Before JUNIT annotation.
It creates the browser driver object which has as effect opening the browser.
b) testScript()
The test script implements a test case.
It uses @Test JUNIT annotation which specifies that the method is a test script.
You can have a test script for each manual test case to be automated.
c) cleanUpEnvironment()
After the test script finished executing, the test environment is cleaned up.
The cleanUpEnvironment() method is responsible for this.
It executes after each test script because of the @After JUNIT annotation.
It destroys the browser driver object and closes the browser.
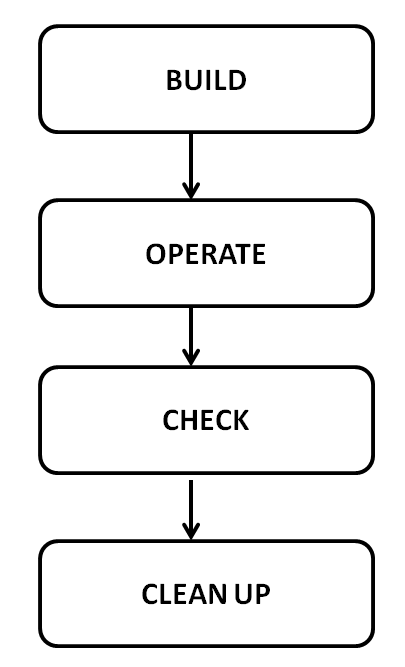
2.2 How a test script is executed
When executed, a test script goes through a few phases:
test environment is built by setUpEnvironment() method
the site is brought to the point where verifications can be done.
verifications are being done.
test environment is cleaned up by cleanUpEnvironment() method.
2.3 Create the template of the test class
What follows is the template of the test class.
The setUpEnvironment(), cleanUpEnvironment() and searchReturnsResults() method are empty at this point.
We will add code to them very soon.
public class Tests {
@Before
public void setUpEnvironment() {
}
@Test
public void searchReturnsResults() {
}
//other test scripts
@After
public void cleanUpEnvironment() {
}
}
2.4 Add code for setUpEnvironment() and cleanUpEnvironment() methods
3 changes are done in this phase:
- WebDriver variable is added to test class
- the driver object is instantiated as FirefoxDriver() in the setUpEnvironment() method
- the driver object is destroyed using driver.quit() in the cleanUpEnvironment() method
public class Tests {
WebDriver driver;
@Before
public void setUpEnvironment() {
driver = new FirefoxDriver();
}
@After
public void cleanUpEnvironment() {
driver.quit();
}
@Test
public void searchReturnsResults() {
}
}
2.5 Add the code for the test script
Next, we add code to the test script.
The code should look as close as possible to the test case.
We will use in the test script the methods for the test case actions (openPage(), searchForKeyword()).
public class Tests {
WebDriver driver;
@Before
public void setUp() {
driver = new FirefoxDriver();
}
@After
public void tearDown() {
driver.quit();
}
@Test
public void searchReturnsResults() {
homePage.open("http://www.vpl.ca");
homePage.searchForKeyword("java");
assertTrue(resultsPage.isOpen() == true);
assertTrue(resultsPage.resultCount() > 0);
}
}
2.6 Create objects for Home Page and Results Page
For the test script to work, the homePage and resultsPage objects are needed.
They are objects of HomePage and ResultsPage classes.
public class Tests {
WebDriver driver;
@Before
public void setUp() {
driver = new FirefoxDriver();
}
@After
public void tearDown() {
driver.quit();
}
@Test
public void searchReturnsResults() {
HomePage homePage = new HomePage(driver);
homePage.openPage("http://www.vpl.ca");
homePage.searchForKeyword("java");
ResultsPage resultsPage = new ResultsPage(driver);
assertTrue(resultsPage.isOpen() == true);
assertTrue(resultsPage.resultCount() > 0);
}
}
If you execute the code at this point, it will not work as the HomePage and ResultsPage classes do not exist yet.
What is important to note for the test script is that
- it does not include any Selenium WebDriver method or objects; the only exception to this rule is the driver variable
- it uses objects of the HomePage and ResultsPage classes to interact with these pages of the site
- it uses JUNIT assertions for verifications
3. CREATE THE HOME PAGE CLASS
HomePage class is the container where user actions for Home Page are implemented.
It is a page object class.
It includes fields and methods.
3.1 Create the template of the home page class
public class HomePage {
/* VARIABLES
element locators
page title
page url
*/
/* METHODS
openPage(url);
searchForKeyword(keyword);
*/
}
3.2 Add the fields and methods to the class
public class HomePage {
//fields
String homePageUrl;
String searchTextBoxLocator;
String searchButtonLocator;
//methods
public void openPage(String url) {
}
public void searchForKeyword(String keyword) {
}
}
3.3 Add values to the class’s fields
public class HomePage {
String homePageUrl = "http://www.vpl.ca";
String searchTextBoxId = "globalQuery";
String searchButtonLocator = "//input[@class='search_button']";
public void openPage(String url) {
}
public void searchForKeyword(String keyword) {
}
}
3.4. Add the WebDriver field and constructor to the class
The HomePage constructor executes automatically when a class object is created.
It takes a WebDriver parameter (driver) that comes from the test script.
The driver parameter is saved in the browserDriver class field.
The HomePage methods use the browserDriver to interact with page elements through Selenium WebDriver methods.
public class HomePage {
WebDriver browserDriver;
String homePageUrl = "http://www.vpl.ca";
String searchTextBoxId = "globalQuery";
String searchButtonLocator = "//input[@class='search_button']";
public HomePage (WebDriver driver) {
browserDriver = driver;
}
public void openPage(String url) {
}
public void searchForKeyword(String keyword) {
}
}
3.5. Implement the methods
HomePage class uses 2 types of methods:
PUBLIC
These methods correspond to test case actions and are used in the test script:
openPage(String url)
searchForKeyword(String keyword)
PRIVATE
These methods are helper methods for the public methods.
They correspond to sub-actions and are used in the HomePage class only:
typeSearchKeyword(String keyword)
executeSearch()
public class HomePage {
WebDriver browserDriver;
String homePageUrl = "http://www.vpl.ca";
String searchTextBoxId = "globalQuery";
String searchButtonLocator = "//input[@class='search_button']";
public HomePage (WebDriver driver) {
browserDriver = driver;
}
public void openPage(String url) {
browserDriver.get(homePageUrl);
}
public void searchForKeyword(String keyword) {
typeSearchKeyword(keyword);
executeSearch();
}
private void typeSearchKeyword(String keyword) {
WebElement searchTextBox = browserDriver.findElement(
By.id(searchTextBoxId));
searchTextBox.click();
searchTextBox.clear();
searchTextBox.sendKeys(keyword);
}
private void executeSearch() {
WebElement searchTextButton = browserDriver.findElement(
By.xpath(searchButtonLocator));
searchTextButton.click();
}
}
Quick explanation of how the methods work:
openPage(url)
- opens the url in the browser
typeSearchKeyword(String keyword)
- finds search textbox element using its locator
- clicks search textbox element
- clears existing value from the textbox (if any)
- types keyword in the textbox
executeSearch()
- finds search button element using its locator
- clicks search button element
searchForKeyword(keyword)
- types keyword in search text box using the typeSearchKeyword() method
- executes the search using the executeSearch() method
4. CREATE THE RESULTS PAGE CLASS
ResultsPage class is the container where all user actions for Results Page are implemented.
It is a page object class.
It includes fields and methods.
4.1. Create the template of the results page
public class ResultsPage {
/* FIELDS
element locators
page title
page url
*/
/* METHODS
isOpen()
resultCount()
*/
}
4.2. Add the fields and methods to the class
public class ResultsPage {
//fields
String resultCountLocator;
String resultsPageTitle;
String resultsPageUrl;
//methods
public boolean isOpen() {
}
public int resultCount() {
}
}
4.3. Add values to the fields of the class
public class ResultsPage {
String resultCountLocator = "//span[@class='items_showing_count']";
String resultsPageTitle = "Search | Vancouver Public Library | BiblioCommons";
String resultsPageUrl = "https://vpl.bibliocommons.com/search?q=java&t=keyword";
public boolean isOpen() {
}
public int resultCount() {
}
}
4.4. Add the WebDriver field and constructor to the class
ResultsPage constructor executes automatically when a class object is created.
It takes a WebDriver parameter (driver) that comes from the test script.
The driver parameter is saved in the browserDriver class field.
ResultsPage methods use browserDriver to interact with page elements through Selenium WebDriver methods.
public class ResultsPage {
WebDriver browserDriver;
String resultCountLocator = "//span[@class='items_showing_count']";
String resultsPageTitle = "Search | Vancouver Public Library | BiblioCommons";
String resultsPageUrl = "https://vpl.bibliocommons.com/search?q=java&t=keyword";
public ResultsPage(WebDriver driver) {
browserDriver = driver;
}
public boolean isOpen() {
}
public int resultCount() {
}
}
4.5. Implement the methods
public class ResultsPage {
WebDriver browserDriver;
String resultCountLocator = "//span[@class='items_showing_count']";
String expectedResultsPageTitle = "Search | Vancouver Public Library | BiblioCommons";
String expectedResultsPageUrl = "https://vpl.bibliocommons.com/search?q=java&t=keyword";
public ResultsPage(WebDriver driver) {
browserDriver = driver;
}
public boolean isOpen() {
boolean isTitleCorrect = browserDriver.getTitle()
.equalsIgnoreCase(
expectedResultsPageTitle);
boolean isUrlCorrect = browserDriver.getCurrentUrl()
.equalsIgnoreCase(
expectedResultsPageUrl);
return isTitleCorrect && isUrlCorrect;
}
public int resultCount() {
WebElement resultCountLabel = browserDriver.findElement(
By.xpath(resultCountLocator));
String resultCountText = resultCountLabel.getText();
return extractNumberFromResultCountText(resultCountText);
}
private int extractNumberFromResultCountText(String resultCountText) {
int startIndex = resultCountText.indexOf("of") + 3;
int endIndex = resultCountText.indexOf(" items");
return Integer.parseInt(resultCountText
.substring(startIndex, endIndex));
}
}
Quick explanation of how the methods work:
isOpen()
- gets the page title and compares it with the expected value
- gets the page url and compares it with the expected value
extractNumberFromResultCountText(resultCountText)
- extracts the number from the result count label text
resultCount()
- finds the result count label element
- gets the value of the result count label element
- extracts the number from the result count label
- returns the number
This is it!
You should have a good idea now about how to use the page object model to create page object classes.
Questions or feedback?
Please leave them in the Comments section!
What is next?
Page object model is much more than creating classes for all pages of the site.
For good test automation code, you should also learn about
- returning page objects from page methods
- creating page element classes
- creating a base class for a generic page
- using Page Factory
- using the LoadableComponent class
- using the SlowLoadableComponent class
I am using all these in my daily automation work and I think that you should use them too.
Read more here.
![odd-one-out[1]](https://seleniumjava.com/wp-content/uploads/2017/12/odd-one-out1.jpg?w=730)














You must be logged in to post a comment.